🚀 llms.txt are live on SN33
The llms.txt repository is now live. 🔗 http://github.com/afterpartyai/llms_txt_store
SN33 has processed the first batch with over 1,000 websites crawled, cleaned, and converted into structured llms.txt files by the subnet.
Semantic summaries ready for any LLM agent, MCP server, or AI app to consume instantly. No scraping. No parsing raw HTML. Just clean, machine-readable intelligence.
New batches will be pushed as the subnet keeps processing. The repo grows every week.
What's in the dataset:
→ Structured semantic summaries per domain
→ Named entities: people, orgs, products, technologies, concepts
→ Topic classification and key themes
→ Deterministic O(1) lookup by domain with no index file needed
→ Git-friendly structure that scales to millions of domains
This initial release covers ~1,000 domains as a pilot, but the pipeline scales to millions.
📍 Roadmap: 10K → 100K → 1M domains → continuous updates from new Common Crawl releases and soon from requests.
🌍 And the frontend is coming.
Any domain. You request it, the subnet processes it, you get an llms.txt back. We're putting the finishing touches on the public UI and it drops soon.
SN33 is becoming infrastructure. The web, made readable for machines and open to anyone, powered by decentralized infra.
Star the repo. Share it. And stay close. The next drop is right around the corner.
LinkedIn
Same conversation three times this past week with CRE acquisitions analysts at different firms:
"DealPath is great at tracking my pipeline. RedIQ is great at pulling numbers off a T-12. But when it's 9pm and I have to decide if this deal fits our buy box, I'm still in Excel."
The tools track. They don't analyze.
Every firm has an investment thesis. A return profile, a market footprint, rent-growth assumptions the IC has already signed off on. None of the category leaders know any of that and they can't, because they're pipeline software, not investment software.
So the first real acquisitions question, is this deal in our box?, still lands on a human with a spreadsheet.
That's the gap AcquiOS was built for:
→ OM to memo-ready model in minutes
→ Every broker assumption pressure-tested against market comps, rent, cap rate, vacancy, expenses, before the model runs
→ Every deal scored against your specific buy box (AcquiScore 0–100, PROCEED, CAUTION, PASS), not a generic template
→ Pipeline tracking as the byproduct, not the product
This isn't a Dealpath replacement. Dealpath is a pipeline. AcquiOS is the question above the pipeline: does this deal even belong in it?
If your analysts are burning 4 hours on a deal only to pass, you already know the problem. Would love to show you the other side.
Commercial real estate is one of the few industries AI won't commoditize. Not because the work is too complex. It's because sellers don't just pick offers.
They pick buyers.
You can't buy shares in a building. You have to buy the whole asset, and someone has to actually choose to sell it to you. A seller who's held a property for twenty years isn't just looking for the highest number. They're looking for certainty.
Certainty that you'll close, that you won't retrade at the eleventh hour, that your process will run smoothly without any hiccups. Brokers are making that same call every time they decide who to send a deal to: is this the buyer I trust to get it done?
That trust gets built one handshake at a time. It's why this will always be a relationship business.
But that isn't an excuse to ignore the technology.
Your relationships are exactly what create your information advantages in the first place. The problem is those advantages tend to stay stuck in your head, in an associate's inbox, buried somewhere in an email thread.
AI doesn't replace the handshake. It becomes your 2nd brain. Gathering intelligence from those handshakes and putting it in the hands of everyone on your team, in real-time.
Relationships get you the first look. The ability to organize, scale, and act on what you learn is what actually closes the deal.
We've stopped doing traditional software demos at AcquiOS. Now, we do "reverse demos".
Everyone in commercial real estate is evaluating AI right now. But the way we used to buy software was fundamentally broken.
A sales rep shares their screen, clicks through a perfectly rehearsed workflow, and 30 minutes later, your acquisitions team is left wondering:
"Will this actually handle a messy OM or a scanned T12?"
The rest of the tech world figured this out years ago. Proptech is still catching up.
We're flipping the script by borrowing a format from Clay: the "reverse demo."
Instead of a generic walkthrough, we changed the rules:
→ You share your screen
→ You upload your own offering memorandum
→ You drive the platform
There are no perfectly curated sandboxes. Just total transparency.
When a firm brings their own deal data, they see exactly how the system handles the real world.
No guessing, just proof.
It's infinitely better than a standard free trial, because you aren't left alone to figure it out. We'll be sitting right next to you, guiding you through underwriting your own deal, in real time.
No one should have to take a leap of faith on AI.
The companies that win the next decade of real estate tech won't be the ones with the slickest slide decks. They'll be the ones brave enough to hand you the keys from minute one.
Ready to take a reverse demo of AcquiOS? Send me a DM.

Pretty big news today. Appetite for AI compute is endless. Having built AcquiOS on Claude and AWS it is no surprise.
Anthropic just committed to spend over $100 billion on AWS over the next 10 years. 5 gigawatts of compute. Trainium chips through the next several generations.
Why does this matter for us?
AcquiOS is built on Claude. It's the model we've consistently found most effective for financial analysis work like underwriting, rent roll reconciliation, etc. We're in the Claude Partner Network and we've been working closely with their team as we build.
We also deploy AcquiOS for our enterprise customers inside their own private AWS environments. So when Anthropic goes deeper on AWS, it means better performance, lower costs, and more compute for the exact infrastructure our customers are already running on.
Excited about what's ahead.
Most CRE acquisition teams still spend 5–10 hours building a single IC model.
In 2026, that's no longer a competitive stance. It's a liability.
That's the conversation I'm looking forward to at IMN's Real Estate Private Funds Summer, June 24–26 in Newport, RI, where I'll be joining the AI panel alongside some terrific peers.
At AcquiOS, we're collapsing that 10-hour workflow into minutes: OM → fully-modeled deal in your template, with citations on every number and an AcquiScore that actually reflects your investment criteria.
Excited to swap perspectives on where private funds go from here.
Register with code REU2864SPK for 20% off.

Your top analyst just put in their two weeks notice.
But the biggest loss isn't the talent walking out the door. It's the multi-million dollar underwriting model they're leaving behind.
When they started, that spreadsheet was a clean, standardized baseline.
Then, the mutations began.
The team spent hours bolting on different pieces for a complex debt structure, a phased development timeline, and a highly specific Investment Committee request.
Before long, the model mutated into a fragile web of cross-sheet references.
The problem now is that your departing analyst is the only person on the team who actually knows how to get it to all calculate. If the hire meant to replace them changes one wrong cell, the entire thing falls apart.
All that undocumented expertise just walked into an elevator, leaving you to rely on a Frankenstein spreadsheet held together by three hidden cells nobody else understands.
The smartest teams are killing this cycle.
They aren't forcing their analysts to build and maintain fragile models.
They're using AI to ingest offering memorandums, extract the data, and instantly generate clean, fully functional financial models in their approved templates.
When your underwriting relies on manual formula adjustments, you aren't just frustrating your best talent. You're creating a massive operational liability.
Analysts want to evaluate real estate, not play mechanic to a dying Excel file.
If your entire pipeline depends on one associate's ability to keep a spreadsheet alive, you don't have an underwriting advantage. You have a single point of failure.

It's 2:00 AM, and your top analyst is still at the office. They're manually copying numbers from ARGUS into your master Excel model.
You probably think this shows dedication and grit. In reality, it's a massive, unhedged financial liability.
We treat late-night formatting sessions as a badge of honor in commercial real estate. We call it "paying your dues."
But relying on an exhausted human to flawlessly transfer data between ARGUS, Excel, and PowerPoint is NOT rigorous underwriting. It's a gamble.
One wrong keystroke in a pro forma can mis-price an asset by millions. A single broken formula, buried deep in a spreadsheet after midnight, can blow up an entire deal or cost your investors a fortune.
How much investor capital is currently riding on an associate's ability to stay awake? And how happy are you to make that gamble?

A month ago, maybe one in four people in commercial real estate had used Claude. Today, awareness is closer to 100%.
And it should be. Claude is an incredible tool for each individual on the team. But there's a massive difference between using AI as an individual productivity tool for one-off tasks and leveraging it to its full potential as an organization.
Right now, most teams are taking the first approach. The VP pushes for everyone to have a $20/month Enterprise subscription. Their analysts open a chat window, drop in a financial model, and use the AI to trace formulas or speed up a specific task.
But if you push that single thread too far, it breaks. If you upload 50 leases to create a rent roll, you want to utilize all relevant deal information on deals you've already looked at, you need an AI-native system powered by Claude.
The real unlock for commercial real estate isn't just giving your analysts a faster calculator. It's building AI into your core processes as an organization. The firms building for the future today are starting to weave it into their firm's DNA.
The self-storage industry has a $50B+ fragmentation problem.
There are more individual-owned storage facilities in the US than Starbucks locations. Most have been held 15–25 years by the same family. No broker. No listing. No online presence.
That's the opportunity. But reaching them has always been the bottleneck.
We built AcquiOS Deal Sourcer to solve it:
→ Identify every self-storage facility in an MSA
→ Filter out the REITs (60–70% of what Google Maps returns)
→ Verify each property against public records
→ Pierce every LLC to find the individual behind the entity
→ Score on acquisition feasibility, not just location quality
→ Deliver verified owner phone numbers for direct outreach
400+ scored targets. 136 LLCs pierced to individuals. 275 verified phone numbers.
This is what the deal sourcing pipeline should look like in 2026.
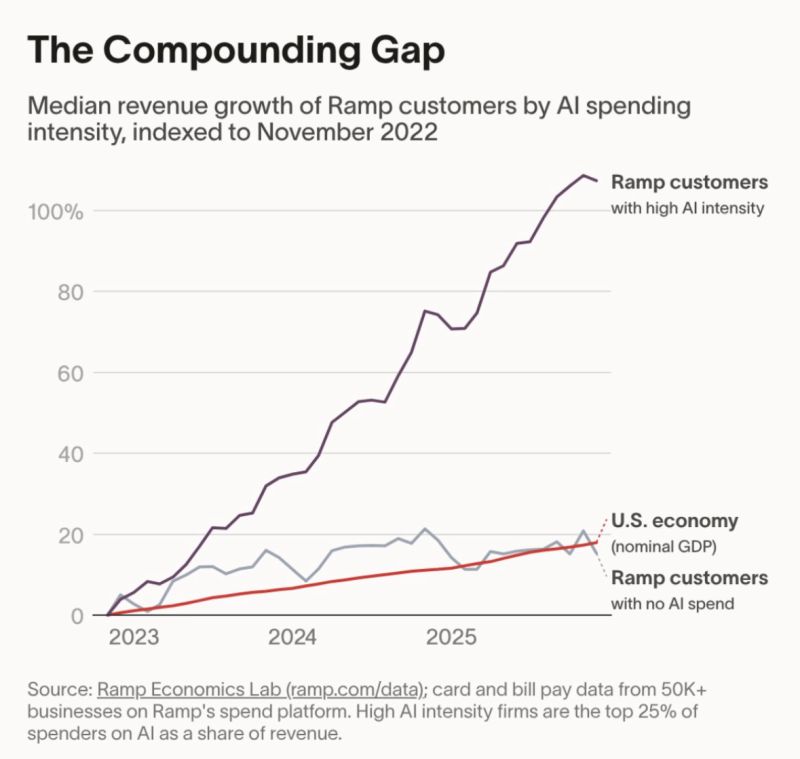
Ramp just dropped the most important chart in business right now. Companies spending heavily on AI are growing revenue 5x faster than those that aren't. And the gap is compounding.
This isn't a tech story. It's a capital allocation story.
In CRE, the parallel is brutal: Your acquisitions team reviews 20+ OMs a month. Each one takes 5–10 hours to model. By the time your analyst builds the DCF, the broker's best-and-final has come and gone.
The firms using AI to underwrite aren't just faster and seeing more deals. They are using AI to project manage the whole due diligence process: killing bad deals earlier (saving thousands in the process) and putting capital to work while everyone else is still in Excel.
And their data COMPOUNDS. We built AcquiOS to put acquisition teams on the right side of this curve, getting you from OM to financial model in minutes, in your template, with every assumption sourced and auditable.
The question isn't whether AI changes real estate. It's what color line on the graph you'll be.
Just wrapped IMN Multifamily in Miami. Heading to DC Finance Family Office Summit in NYC tomorrow. The data is telling the same story in every room: the buying window is opening and most people aren't paying attention.
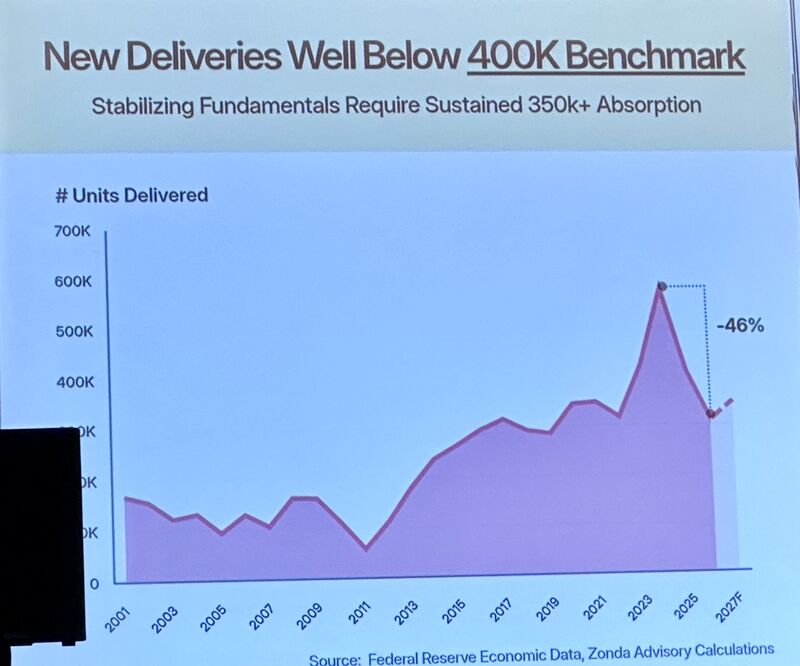
New multifamily deliveries have fallen 46% from peak and are now well below the 400K annual benchmark. Stabilization requires sustained 350K+ absorption and we're getting there fast.
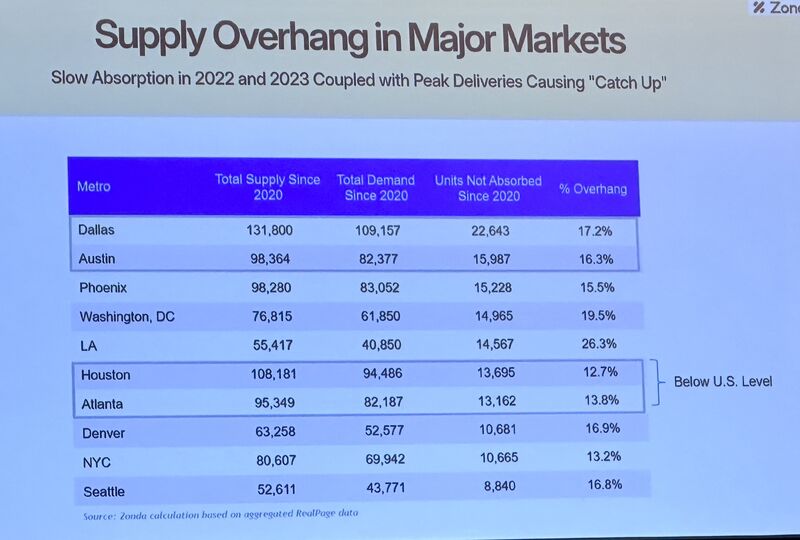
But the overhang is wildly uneven. LA is sitting at 26.3% supply overhang since 2020. DC at 19.5%. Meanwhile Houston (12.7%) and Atlanta (13.8%) are already below the national average.
The Sunbelt markets that looked overbuilt 18 months ago? They're now backed by permanent, high-wage employment anchors from Samsung's $44B fab in Austin, Fujifilm's $3.2B gigafactory in Raleigh and NeoCity semiconductors in Orlando. This isn't pandemic migration anymore. This is structural.
The supply side is correcting itself. The demand side never left. The capital markets just haven't caught up yet.
Featured On
Hear David on the Podcast Circuit
David Fields, CEO of AcquiOS, shares how AI is reshaping commercial real estate acquisitions.
Get Started
Ready to see AcquiOS in action?
Book a live demo or talk to our team about how AcquiOS fits your workflow.